
얼마전 토스과제를 진행하며 알게된 점들은 매끄러운 사용자경험 및 개발 생산성을 위해
frontend 로직뿐 아니라 보이지 않는 환경설정에도 엄청난 노력을 하고있음을 알게되었다.
이전에 개발을 하며 알고는 있지만 자세하게 몰�랐던 부분과 그들의 디테일에
놀라워하며 면접준비를 했는데 이 글에서는 이 과정에서 알게된 사실들을 정리한다.
Youtube 및 toss tech blog를 참고하여 작성한 글 입니다.
dependencies in Package.json
우리가 개발을하며 패키지매니저를 통해 라이브러리를 설치할 때는
package.json 내의 dependencies 필드를 통해 의존성을 규정하는것으로 설치한다
이때 해당 패키지의 이름과 버전범위를 지정한 객체를 통해 설치하는데
버전의 범위는 하나 혹은 여러개의 공백으로 분리된 문자열이다.
버전범위를 지정하는 자세한 방법은 semver를 참고
만약 개발중에만 필요한 라이브러리일 경우 devDependencies필드를 활용하며
npm install some-package --save-dev
위와 같은 명령어로 설치 가능하고 패키지를 설치 후 devDependencies에 추가한다.
여기서 만약 내가 clone된 repository에서 npm install했을 경우 npm은 이를 프로젝트를
개발중이라고 인식하고 devDependencies에 추가하니 유의할 것.
마지막으로 본인만의 plugin을 만들 때 사용하는 peerDependencies인데
정의에 따르면 상속되는 의존성으로 패키지를 사용하는 곳에서 제공해야하는 의존성이다.
만약 프로젝트 내에서 패키지를 peerDependencies로 명시할 경우 패키지를 제공하는 책임을
가장 상위프로젝트로 바꾸기 때문에 번들링 결과에서 중복을 막을 수 있다.
하지만 이러한 장점에도 치명적인 단점은 의존성 전파문제이다.
package A:
peerDependencies:
"package P"
package B:
dependencies:
"package A"
peerDependencies:
"package P"
package C
dependencies:
"package B"
peerDependencies:
"package P"
위와 같이 peerDependency를 사용하는 package A에서 A를 가지고 있는 모든 패키지들은
A를 사용하지 않음에도 peerDependencies에 추가해주어야 하며 이는 의존성의 관리복잡도를 증가시켜
에러의 확률을 높인다 npm과 같은 패키지매니저들에서 이러한 오류들을 엄밀히 검사하지 않기 때문에
유의해야 하며 따라서 peerDependencies를 사용하는 경우
단 하나의 패키지만 존재해야 하는경우(싱글톤) 일때 사용할 수 있다.
dependencies의 문제점
위와 같은 문제말고도 npm/node_modules의 문제는 유령의존성(Phantom Dependency) 현상이다
node_modules를 사용하는 yarn v1 및 npm에서는 중복해서 설치하는 모듈을 피하기 위해
호이스팅 기법을 사용한다
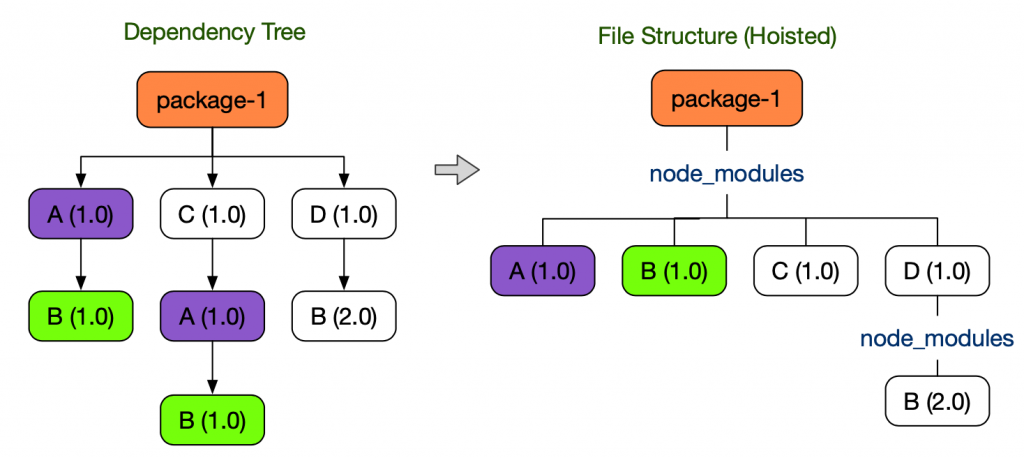
왼쪽과 같은 의존성트리일 경우 디스크공간의 절약을 위해 중복되는 트리를 지우는 과정에서
직접 의존하고 있지 않았던 B(1.0) 패키지를 불러와 사용할 수 있다.
package.json 에 명시하지 않은 라이브러리를 사용할 수 있는 현상을 Phantom Dependency라고 하며
이러한 특성은 시스템을 혼란스럽게 하고 최악의 경우 Runtime Error의 가능성을 높힌다.
토스팀에서는 이러한 문제를 해결하기 위해 Yarn Berry + PnP를 도입하며 해결했다.
Yarn Berry는 Plug'n'Play 전략을 이용하여 기존의 Package.json을 기반으로 의존성 트리를
만들어 node_modules 구조를 생성하던 방식에서 의존성 설치시 node_modules를 생성하지 않고
.yarn/cache폴더에 의존성 정보를 저장한다 또한 .pnp.cjs 파일에 의존성을 찾을 수 있는
정보를 기록하여 효율적인 패키지 관리를 할 수 있다.
yarn은 기존 node.js의 require함수를 덮어씌워 동작하며 효율적인 패키지관리를
할 수 있고 이때문에 특정 패키지와 의존성에 대한 정보가 필요할 때 바로 알 수 있다
또한 Yarn PnP 시스템에서 각 의존성은 Zip 아카이브로 관리하게 되어 다음과 같은 장점이 생긴다
- node_modules가 없음 -> 빠른 설치 가능
- 패키지들은 하나의 Zip아카이브로 저장하여 중복방지
- 파일의 수가 적어지며 변경사항의 감지가 쉬워지고 삭제가 빠르다.
Zero Install
여기서 한발 더 나아가 의존성을 Git으로 관리한다면 어떨까?
일반적인 node_modules의 크기는 1.2GB/13만5천개의 파일을 가지고 있지만 yarn을 사용한다면
139MB/2천개의 압축파일로 줄어든다 이렇게 줄어든 파일크기는 Git으로 관리하여 버전관리에
포함시키고 설치할게 아예없는 환경을 구성한다.(Zero-Install)
토스팀에서 Zero-Install을 사용하며 얻은 장점 두 가지
-
clone 혹은 branch변경시 yarn install 실행x
- 만약 다른 의존성을 사용하는 브랜치로 이동한다면 재설치할 필요가 없다.
-
CI동작시 의존성 설치시간 절약
- cache miss 일경��우 60 ~ 90초 가량 소요되던 시간을 의존성 복제만으로
바로 사용이 가능하여 시간절약
- cache miss 일경��우 60 ~ 90초 가량 소요되던 시간을 의존성 복제만으로
Bundler
javascript에 모듈이라는 개념이 없던시절 규모가 큰 프로그램을 개발하기 위해 파일을 쪼개서 작업했지만
스크립트 태그를 통한 전역변수 참조를 했기때문에 함수나 변수의 이름 충돌 문제를 일으키고
규모가 커질수록 스크립트 로드시간이 증가하여 사용자 경험에 안좋은 영향을 끼쳤다.
이러한 문제를 해결하기 위해 파일을 하나로 합치는 번들링(Bundling) 이라는 개념이 탄생하고
CommonJS의 require함수가 등장하며 이 시점부터 파일단위의 개발이 가능해지고 수천개의
JS파일로 분리하며 라이브러리의 쉬운 재사용성을 통해 더 나은 개발경험을 제공했다.
모듈의 탄생과 함께 생겨난 번들러는 CommonJS이후에도 생겨난 모듈에 의해 설계의 영향을 미쳤고
지금 이시점에도 굉장히 다양한 번들러들이 있지만 번들러의 동작은 크게 세 가지로 구분한다.
- Resolution
- Load
- Optimization
Resolution
resolution단계에서는 import/require되는 파일의 위치를 정확하게 찾는역할
import { App } from './App';
App을 import 하는경우 ./App의 정확한 경로를 탐색한다 (App.js, App.ts, App.tsx)
번들러에서는 이러한 설정을 기본제공하고 필요에따라 커스텀가능.
이렇게 정확한경로를 탐색하여 어떤파일들을 합쳐야 최종결과물이 되는지 알 수 있다.
Load
Load단계에서는 표준 Javascript로 변�환하는 역할을 하는데 현대의 웹 개발은
HTML,CSS,Javascript로만 개발하기엔 어려움이 있고 이를 보완하고자 슈퍼셋 언어들이 등장하였다.
이에 따라 대표적으로 Typescript와 같은언어를 사용하기위해 트랜스파일러가 등장하며
번들링과정에서 Babel/SWC같은 트랜스파일러를 수용하여 표준Javascript 이외에도 사용가능한
형태로 발전해 트랜스파일링 과정을 거치는것이 Load단계에 해당함.
여기서 트랜스파일러는 한 언어를 추상화단계가 비슷한 언어로 변환해주는 역할을하지만
언어 전체적으로 트랜스파일하지는 않는다. 문법의 문제가 아닌 언어의 표준이 변경되거나
새로추가되는 함수의 경우 폴리필(polyfill)과정을 거쳐야한다 구현이 누락된
새로운 기능을 메꿔주는(fill in) 역할을 하며 기능이나 사용자의 브라우저에 따라
다양하게 설정할 수 있다.
Optimization
Resolution/Load 단계를 거쳐 완전한 JS파일 하나를 생성했다면 다양한 의존성을 사용하는
JS파일의 크기는 너무 크기 때문에 성능저하를 유발할 수 있다 따라서 파일 크기를 줄이기위해
두 가지 방법을 사용함
- Minification (Compression + Mangling)
- Tree Shaking
1-1. Minification - Compression 코드의 text를 최대한 압축
- undefined -> void 0
- 2 + 3 -> 5
- !a && !b -> !(a || b)
- Infinity -> 1/0
1-2. Minification - Mangling 변수,Class,파일이름 최적화
// function add(num1, num2) { return num1 + num2 }
function add(l, r) {
return l + r;
}
2. Tree Shaking 사용하지 않는 코드 제거
Tree Shaking 단계에서는 사용하지 않는 코드를 분석하고 제거하는 역할을 하는데
사용하지 않는 코드가 무엇인지 판별하는 일은 까다로운 편에 속한다(정적분석의 어려움)
따라서 번들러별로 알고리즘 및 접근방식이 천차만별이라 큰 차이가 있는 사항이기도 하다.
토스에서는 위와 같은 번들러의 특성을 활용해 React Native의 Metro 에서
ESbuild로 옮기며 빌드속도를 최적화 했던 사례를 소개했다.
Git 분석 및 활용
VCS중 하나인 Git은 델타기반 버전관리 시스템으로 파일의 변화를 시간순으로 관리해
프로젝트의 스냅샷을 저장하고 파일간 변경사항을 차이(diff)/델타(delta) 형태로
저장하고 파일을 세 가지 상태인 Committed, Modified, Staged 관리하며
이 세 가지의 상태는 프로젝트의 세 가지 상태와 연관되어 있고 다음과 같다.
- Working Directory - 실제 작업공간
- Staging Area - 변경된 파일들의 대기공간
- Repository(.git directory) - 최종적으로 저장된 파일들의 공간
Git�은 안전하고 일관된 파일관리를 위해 sha-1 해시알고리즘으로 40자길이의 16진수 문자열을
만들고 모든것을 해시로 식별하여 데이터의 무결성을 확인한다.
Git basic
git으로 버전관리를 시작하기 위해 본인의 작업폴더에서 git init 명령어를 실행하면
.git폴더가 생성되고 이곳에 파일들의 정보가 저장된다.
우리가 실제로 작업하는공간(Working Directory)의 파일은 Tracked와 Untracked로 나누며
Tracked파일의 경우 스냅샷에 포함돼 있던 파일로 Unmodified, Modified, Staged 상태중
하나이다.
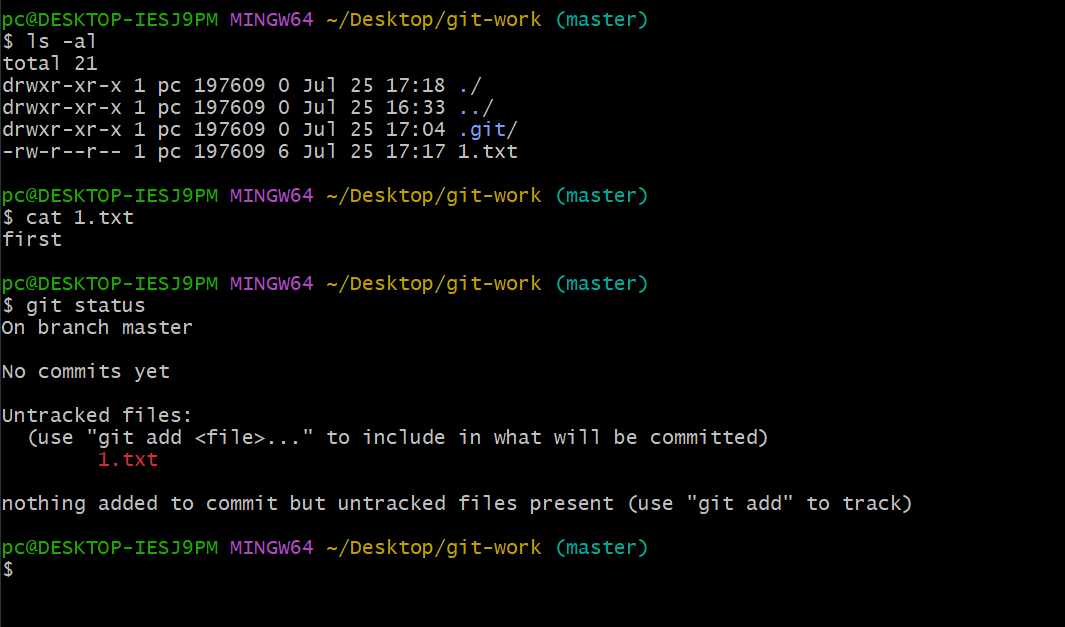
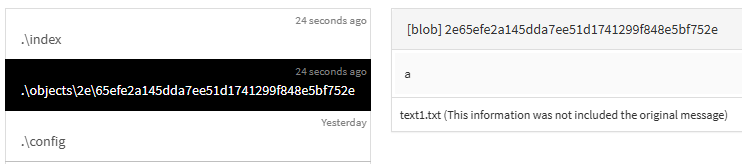
참고
- package.json 번역
- node_modules로부터 우리를 구원해 줄 Yarn Berry
- FECONF 2022 [B4] 내 import 문이 그렇게 이상했나요?
- FECONF 2022 [B2] 일백개 패키지 모노레포 우아하게 운영하기
- FEConf 2023 [B4] React Native, Metro를 넘어서
- 토스ㅣSLASH 22 - 잃어버린 개발자의 시간을 찾아서: 매일 하루를 아끼는 DevOps 이야기
- 토스ㅣSLASH 22 - 잃어버린 유저의 시간을 찾아서 : 100년을 아껴준 SSR 이야기
- JavaScript 번들러의 이해
- Git 내부 동작 파헤치기
- 시작하기 - Git 기초